Docutils: Architecture, Extending, and Embedding
We will describe the architecture of Docutils, how to add functionality to Docutils, and how to use Docutils in your own applications. Not necessarily in that order.
What is Docutils?
Text processing framework (because we need more frameworks)
A set of tools for processing plaintext documentation into useful formats, such as HTML, XML, and LaTeX
111,111 lines of code, tests, & documentation
Split about evenly between the three.
Existing components:
reStructuredText parser
Standalone document, PEP, document tree readers
HTML (+ S5 & PEP), LaTeX, native XML, pseudo-XML writers; experimental (incomplete) writers for OpenDocument, RTF, man page
Internal document model (tree of element & text nodes)
The doctree is the glue that holds everything together.
What is reStructuredText?
WYSIWYG plain-text markup language
Very easy to read, unobtrusive markup
Easy to write
Powerful
Powerful enough for most uses, yet simple enough to fit your brain. (DG) I designed it to fit my brain, which is relatively small.
Extensible
Used for documentation, for taking notes, and for making presentations.
There’s even a book that has been written with reStructuredText (“C++ Template Metaprogramming” by David Abrahams & Aleksey Gurtovoy), but they ran into the limitations of reST and Docutils, so we wouldn't recommend this approach — yet. reStructuredText has to (and will) become more powerful.
Status
Docutils 0.4 released January 9.
Experimental
(That’s what the “0.” means)
API subject to change, but no arbitrary changes
Document model too
A few bugs (details, details)
Lots of to-do items (come join our sprint!)
Yet it’s already very usable! :-)
From release 0.4, micro releases (0.4.x) are bugfix-only. We’re currently working on 0.5.
Existing Uses
Docutils front-end tools (rst2html.py, rst2s5.py, rstpep2html.py, etc.)
Wikis (MoinMoin, ZWiki, Trac, others)
Blogs
PEPs, GLEPs (Gentoo Linux), TIPs (TCL), PEGs (Gzz)
Auto-documentation systems: Epydoc, Pudge, Endo
Roundup
Documentation: from NASA to the William Tyndale Society Journal
What’s Missing?
Major features:
Plugin support
There are many existing extensions to Docutils (mostly in the sandbox), but they aren’t easily usable as plugins.
We want to be able to specify “use extension X, Y, and Z” from the command line, or have a directory for auto-loaded plugins, or both.
If you're a plugin guru, we could use your advice!
Python source reader
This was the original “itch” that Docutils was created to “scratch”, but the PySource reader isn’t functional yet.
Sprint! (Hint, hint)
Nested inline markup
Many more things (better GUI, reStructuredText writer, <insert your idea here>, ...)
See the to-do list.
Please come to the Docutils Sprint and help out!
Component Architecture
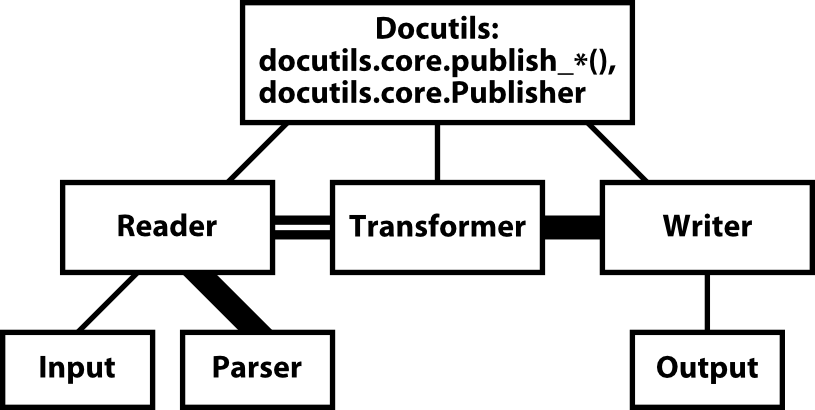
In the component diagram, thick solid lines denote the transfer of standard document tree data. The double line between Reader and Transformer denotes a possibly non-standard document tree.
Data Flow (1)
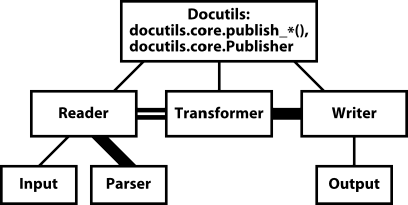
Docutils components are selected at run time by the client application or front end.
The Publisher calls the Reader.
The Reader understands the context of the input. For example, the PEP Reader knows that PEPs begin with an RFC-822-style header, that a table of contents should be added after the header, and that all hyperlinks should be collected near the end of the document.
Typical text files use the Standalone Reader. To extract docstrings & comments from Python source code, you’d use the Python Source Reader (under active development). To reprocess an existing document tree, use the doctree Reader.
The Reader calls an Input object to gather text data.
The Input classes provide a uniform interface for reading from arbitrary low-level input sources, such as files, strings, and even pre-parsed document trees. Input objects handle the decoding of input text to Unicode. Unicode is exclusively used internally.
The Reader calls the Parser, passing the input text.
There are currently two parsers installed in Docutils: the reStructuredText Parser, and the "Null" parser (used for reprocessing existing document trees, in conjunction with the doctree Reader and Input class). The parser generates a document tree, a tree of element and Text nodes, and returns it to the Reader.
The Reader returns the doctree(s) to the Publisher.
Data Flow (2)
The Publisher runs the Transformer.
The Transformer applies various Transforms to the document tree, in a pre-determined order. Transforms modify the document tree in-place: resolving references, numbering sections, creating tables of contents, and performing other functions on the entire document or parts of the document.
The Transformer returns the doctree to the Publisher.
At this point, the doctree is standard, no matter what Parser was used or Reader context was in place.
The Publisher calls the Writer.
The Writer translates the document tree to a format like HTML or LaTeX.
The Writer sends the result to an Output object.
As with Input, the Output object provides a uniform interface for writing to arbitrary low-level destinations, such as files and strings. Output objects also handle text encoding.
The Publisher directly calls only the Reader, the Transformer, and the Writer. However it manages all objects (Input, Output, Reader, Parser, Transformer, Transform, and Writer instances) and passes them where they are needed. For example, the Input and Parser objects are passed to the Reader.
All of this complexity is encapsulated in the Publisher convenience functions; more on these later.
Document Tree
Sample input text:
""" I like the Python_ language. .. _Python: http://www.python.org/ """
Resulting doctree:
<document source="doctree-demo.txt">
<paragraph>
I like the
<reference
refuri="http://www.python.org/">
Python
language.
The document tree data structure is similar to a DOM tree, but with specific node names (classes) instead of DOM’s generic nodes. The schema is documented in an XML Document Type Definition (DTD), which comes in two parts:
the Docutils Generic DTD, docutils.dtd, and
the OASIS Exchange Table Model, soextbl.dtd.
The DTD defines a rich set of elements, suitable for many input and output formats. The DTD retains all information necessary to reconstruct the original input text, or a reasonable facsimile thereof.
The document tree holds the components of Docutils together. The document tree is the unifying intermediate data structure used internally throughout Docutils, first created by the Parser and translated by the Writer. The``docutils.nodes`` module is a class library implementing the nodes of the document tree.
Docutils as a Library (1)
How to use Docutils from your own application.
Convenience functions, from docutils.core:
publish_cmdline(writer_name='html', description='...')The publish_cmdline function is used by all the front-end tools provided with Docutils. The example above is from rst2html.py.
publish_file(source_path='test.txt', destination_path='test.tex', writer_name='latex')You can also pass file objects in the source and destination parameters.
input = get_rst_document() output = publish_string(source=input, writer_name='html')This is what is typically used in wikis and similar applications.
Docutils as a Library (2)
publish_doctree:
>>> input = open('test.txt', 'r') >>> document = publish_doctree(source=input) >>> print document.pformat() <document source="<string>"> <paragraph> This is a test. >>> print document[0].pformat() <paragraph> This is a test.
Docutils as a Library (3)
publish_from_doctree:
>>> output = publish_from_doctree( ... document, writer_name='html') >>> print output <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE html PUBLIC ...> <html xmlns="..." xml:lang="en" lang="en"> <head>...</head> <body> <div class="document"> <p>This is a test.</p> </div> </body> </html>
Nabu uses the publish_doctree and publish_from_doctree functions.
Extending Docutils
Docutils is completely modular. New components of all types can be added:
Readers
Parsers
Writers
Transforms
Test-First Development
The Test Suite
based on unittest.py
but with
significant additions
data-driven
we have Test modules & test packages
test_*.py
test_*/
(requires an __init__.py module; a real package!)
1000 tests!
(DG) I first learned unit testing when I began Docutils. There is absolutely no way I could have developed Docutils without unit testing.
Extending reST
reStructuredText has three extension mechanisms:
directives
interpreted text roles
language translations
19 languages supported: English, German, French, Dutch, Italian, Russian, Esperanto, Japanese, Chinese (simplified & traditional!) ... and it’s easy to add new languages
Language Example
German input text(“bild” is German for “image”):
""" .. bild:: test.png """
Process with this command line:
rst2html.py --language de test.txt test.html
Write a Transform
Sprint!
Join the Docutils sprint!
We will both be here for all 4 sprint days.
And that’s just the beginning!
Did we mention the sprint?
Thanks for listening!
Questions? We’ve got answers!